

Microsoft’s AI red team is excited to share our whitepaper, “Lessons from Red Teaming 100 Generative AI Products.”
The AI red team was formed in 2018 to address the growing landscape of AI safety and security risks. Since then, we have expanded the scope and scale of our work significantly. We are one of the first red teams in the industry to cover both security and responsible AI, and red teaming has become a key part of Microsoft’s approach to generative AI product development. Red teaming is the first step in identifying potential harms and is followed by important initiatives at the company to measure, manage, and govern AI risk for our customers. Last year, we also announced PyRIT (The Python Risk Identification Tool for generative AI), an open-source toolkit to help researchers identify vulnerabilities in their own AI systems.

Pie chart showing the percentage breakdown of products tested by the Microsoft AI red team. As of October 2024, we had red teamed more than 100 generative AI products.
With a focus on our expanded mission, we have now red-teamed more than 100 generative AI products. The whitepaper we are now releasing provides more detail about our approach to AI red teaming and includes the following highlights:
Our AI red team ontology, which we use to model the main components of a cyberattack including adversarial or benign actors, TTPs (Tactics, Techniques, and Procedures), system weaknesses, and downstream impacts. This ontology provides a cohesive way to interpret and disseminate a wide range of safety and security findings.
Eight main lessons learned from our experience red teaming more than 100 generative AI products. These lessons are geared towards security professionals looking to identify risks in their own AI systems, and they shed light on how to align red teaming efforts with potential harms in the real world.
Five case studies from our operations, which highlight the wide range of vulnerabilities that we look for including traditional security, responsible AI, and psychosocial harms. Each case study demonstrates how our ontology is used to capture the main components of an attack or system vulnerability.

Lessons from Red Teaming 100 Generative AI Products
Discover more about our approach to AI red teaming.
Microsoft AI red team tackles a multitude of scenarios
Over the years, the AI red team has tackled a wide assortment of scenarios that other organizations have likely encountered as well. We focus on vulnerabilities most likely to cause harm in the real world, and our whitepaper shares case studies from our operations that highlight how we have done this in four scenarios including security, responsible AI, dangerous capabilities (such as a model’s ability to generate hazardous content), and psychosocial harms. As a result, we are able to recognize a variety of potential cyberthreats and adapt quickly when confronting new ones.
This mission has given our red team a breadth of experiences to skillfully tackle risks regardless of:
System type, including Microsoft Copilot, models embedded in systems, and open-source models.
Modality, whether text-to-text, text-to-image, or text-to-video.
User type—enterprise user risk, for example, is different from consumer risks and requires a unique red teaming approach. Niche audiences, such as for a specific industry like healthcare, also deserve a nuanced approach.
Top three takeaways from the whitepaper
AI red teaming is a practice for probing the safety and security of generative AI systems. Put simply, we “break” the technology so that others can build it back stronger. Years of red teaming have given us invaluable insight into the most effective strategies. In reflecting on the eight lessons discussed in the whitepaper, we can distill three top takeaways that business leaders should know.
Takeaway 1: Generative AI systems amplify existing security risks and introduce new ones
The integration of generative AI models into modern applications has introduced novel cyberattack vectors. However, many discussions around AI security overlook existing vulnerabilities. AI red teams should pay attention to cyberattack vectors both old and new.
Existing security risks: Application security risks often stem from improper security engineering practices including outdated dependencies, improper error handling, credentials in source, lack of input and output sanitization, and insecure packet encryption. One of the case studies in our whitepaper describes how an outdated FFmpeg component in a video processing AI application introduced a well-known security vulnerability called server-side request forgery (SSRF), which could allow an adversary to escalate their system privileges.
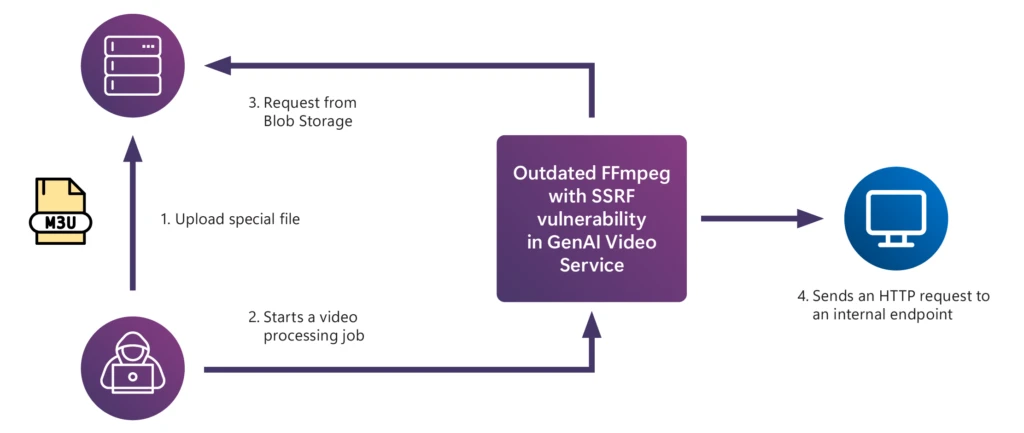 Illustration of the SSRF vulnerability in the video-processing generative AI application.
Illustration of the SSRF vulnerability in the video-processing generative AI application.
Model-level weaknesses: AI models have expanded the cyberattack surface by introducing new vulnerabilities. Prompt injections, for example, exploit the fact that AI models often struggle to distinguish between system-level instructions and user data. Our whitepaper includes a red teaming case study about how we used prompt injections to trick a vision language model.
Red team tip: AI red teams should be attuned to new cyberattack vectors while remaining vigilant for existing security risks. AI security best practices should include basic cyber hygiene.
Takeaway 2: Humans are at the center of improving and securing AI
While automation tools are useful for creating prompts, orchestrating cyberattacks, and scoring responses, red teaming can’t be automated entirely. AI red teaming relies heavily on human expertise.
Humans are important for several reasons, including:
Subject matter expertise: LLMs are capable of evaluating whether an AI model response contains hate speech or explicit sexual content, but they’re not as reliable at assessing content in specialized areas like medicine, cybersecurity, and CBRN (chemical, biological, radiological, and nuclear). These areas require subject matter experts who can evaluate content risk for AI red teams.
Cultural competence: Modern language models use primarily English training data, performance benchmarks, and safety evaluations. However, as AI models are deployed around the world, it is crucial to design red teaming probes that not only account for linguistic differences but also redefine harms in different political and cultural contexts. These methods can be developed only through the collaborative effort of people with diverse cultural backgrounds and expertise.
Emotional intelligence: In some cases, emotional intelligence is required to evaluate the outputs of AI models. One of the case studies in our whitepaper discusses how we are probing for psychosocial harms by investigating how chatbots respond to users in distress. Ultimately, only humans can fully assess the range of interactions that users might have with AI systems in the wild.
Red team tip: Adopt tools like PyRIT to scale up operations but keep humans in the red teaming loop for the greatest success at identifying impactful AI safety and security vulnerabilities.
Takeaway 3: Defense in depth is key for keeping AI systems safe
Numerous mitigations have been developed to address the safety and security risks posed by AI systems. However, it is important to remember that mitigations do not eliminate risk entirely. Ultimately, AI red teaming is a continuous process that should adapt to the rapidly evolving risk landscape and aim to raise the cost of successfully attacking a system as much as possible.
Novel harm categories: As AI systems become more sophisticated, they often introduce entirely new harm categories. For example, one of our case studies explains how we probed a state-of-the-art LLM for risky persuasive capabilities. AI red teams must constantly update their practices to anticipate and probe for these novel risks.
Economics of cybersecurity: Every system is vulnerable because humans are fallible, and adversaries are persistent. However, you can deter adversaries by raising the cost of attacking a system beyond the value that would be gained. One way to raise the cost of cyberattacks is by using break-fix cycles.1 This involves undertaking multiple rounds of red teaming, measurement, and mitigation—sometimes referred to as “purple teaming”—to strengthen the system to handle a variety of attacks.
Government action: Industry action to defend against cyberattackers and
failures is one side of the AI safety and security coin. The other side is
government action in a way that could deter and discourage these broader
failures. Both public and private sectors need to demonstrate commitment and vigilance, ensuring that cyberattackers no longer hold the upper hand and society at large can benefit from AI systems that are inherently safe and secure.
Red team tip: Continually update your practices to account for novel harms, use break-fix cycles to make AI systems as safe and secure as possible, and invest in robust measurement and mitigation techniques.
Advance your AI red teaming expertise
The “Lessons From Red Teaming 100 Generative AI Products” whitepaper includes our AI red team ontology, additional lessons learned, and five case studies from our operations. We hope you will find the paper and the ontology useful in organizing your own AI red teaming exercises and developing further case studies by taking advantage of PyRIT, our open-source automation framework.
Together, the cybersecurity community can refine its approaches and share best practices to effectively address the challenges ahead. Download our red teaming whitepaper to read more about what we’ve learned. As we progress along our own continuous learning journey, we would welcome your feedback and hearing about your own AI red teaming experiences.
Learn more with Microsoft Security
To learn more about Microsoft Security solutions, visit our website. Bookmark the Security blog to keep up with our expert coverage on security matters. Also, follow us on LinkedIn (Microsoft Security) and X (@MSFTSecurity) for the latest news and updates on cybersecurity.
¹ Phi-3 Safety Post-Training: Aligning Language Models with a “Break-Fix” Cycle




GIPHY App Key not set. Please check settings