

Listen to this article

In the field of robotics, vision-based learning systems are a promising strategy for enabling machines to interpret and interact with their environment, said the AI Institute today. It introduced the Theia vision foundation model to facilitate robot training.
Vision-based learning systems must provide robust representations of the world, allowing robots to understand and respond to their surroundings, said the AI Institute. Traditional approaches typically focus on single-task models—such as classification, segmentation, or object detection—which individually do not encapsulate the diverse understanding of a scene required for robot learning.
This shortcoming highlights the need for a more holistic solution capable of interpreting a broad spectrum of visual cues efficiently, said the Cambridge, Mass.-based institutewhich is developing Theia to address this gap.
In a paper published in the Conference on Robot Learning (CoRL), the AI Institute introduced Theia, a model that is designed to distill the expertise of multiple off-the-shelf vision foundation models (VFMs) into a single model. By combining the strengths of multiple different VFMs, each trained for a specific visual task, Theia generates a richer, unified visual representation that can be used to improve robot learning performance.
Robot policies trained using Theia’s encoder achieved a higher average task success rate of 80.97% when evaluated against 12 robot simulation tasks, a statistically significant improvement over other representation choices.
Furthermore, in real robot experiments, where the institute used behavior cloning to learn robot policies across four multi-step tasks, the trained policy success rate using Theia was on average 15 percentage points higher than policies trained using the next-best representation.
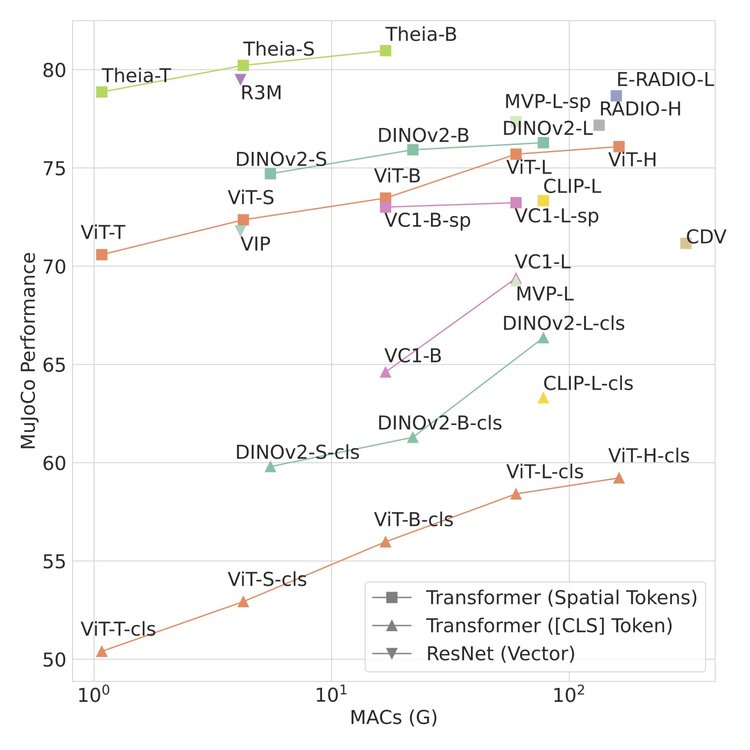
Robot control policies trained with Theia outperform policies trained with alternative representations on MuJoCo robot simulation tasks, with much less computation, measured by the number of Multiply-Accumulate operations in billions (MACs). Source: The AI Institute
Theia designed to combine visual models
Theia’s design is based on a distillation process that integrates the strengths of multiple VFMs such as CLIP (vision language), DINOv2 (dense visual correspondence), and ViT (classification), among others. By carefully selecting and combining these models, Theia is able to produce robust visual representations that can improve downstream robot learning performance, said the AI Institute.
At its core, Theia consists of a visual encoder (backbone) and a set of feature translators, which work in tandem to incorporate the knowledge from multiple VFMs into a unified model. The visual encoder generates latent representations that capture diverse visual insights.
These representations are then processed by the feature translators, which refine them by comparing the output features against ground truth. This comparison serves as a supervisory signal, optimizing Theia’s latent representations to enhance their diversity and accuracy.
These optimized latent representations are subsequently used to fine-tune policy learning models, enabling robots to perform a wide range of tasks with greater accuracy.
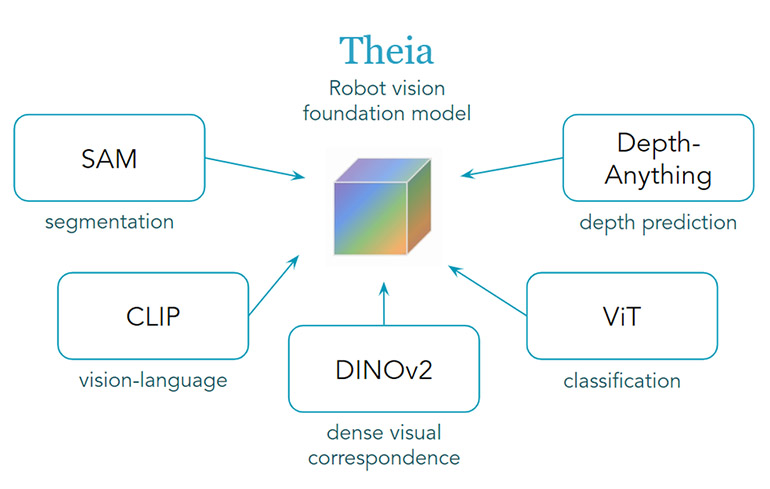
Theia’s design is based on a process that distills the strengths of multiple VFMs, including CLIP, SAM, DINOv2, Depth-Anything, and ViT, among others. Source: The AI Institute
Robots learn in the lab
Researchers at the AI Institute tested Theia in simulation and on a number of robot platforms, including Boston Dynamics‘ Spot and a WidowX robot arm. For one of the rounds of lab testing, it used Theia to train a policy enabling a robot to open a small microwave, place toy food inside, and close the microwave door.
Previously, researchers would have needed to combine all the VFMs, which is slow and computationally expensive, or select which VFM to use to represent the scene in front of the robot. For example, they could choose a segmentation image from a segmentation model, a depth image from a depth model, or a text class name from an image classification model. Each provided different types and granularity of information about the scene.
Generally, a single VFM might work well for a single task with known objects but might not be the right choice for other tasks or other robots.
With Theia, the same image from the robot can be fed through the encoder to generate a single representation with all the key information. That representation can then be input into Theia’s segmentation decoder to output a segmentation image. The same representation can be input into Theia’s depth decoder to output a depth image, and so on.
Each decoder uses the same representation as input because the shared representation possesses the information required to generate all the outputs from the original VFMs. This streamlines the training process and making actions transferable to a broader range of situations, said the researchers.
While it sounds easy for a person, the microwaving task represents a more complex behavior because it requires successful completion of multiple steps: picking up the object, placing it into the microwave, and closing the microwave door. The policy trained with Theia is among the top performers for each of these steps, comparable only to E-RADIO, another approach which also combines multiple VFMs, although not specifically for robotics applications.

Researchers used Theia to train a policy enabling a robot arm to microwave various types of toy food. Source: The AI Institute
Theia prioritizes efficiency
One of Theia’s main advantages over other VFMs is its efficiency, said the AI Institute. Training Theia requires about 150 GPU hours on datasets like ImageNet, reducing the computational resources needed compared to other models.
This high efficiency does not come at the expense of performance, making Theia a practical choice for both research and application. With a smaller model size and reduced need for training data, Theia conserves computational resources during both the training and fine-tuning processes.
AI Institute sees transformation in robot learning
Theia enables robots to learn and adapt more quickly and effectively by refining knowledge from multiple vision models into compact representations for classification, segmentation, depth prediction, and other modalities.
While there is still much work to be done before reaching a 100% success rate on complex robotics tasks using Theia or other VFMs, Theia makes progress toward this goal while using less training data and fewer computational resources.
The AI Institute invited researchers and developers to explore Theia and further evaluate its capabilities to improve how robots learn and interpret their environments.
“We’re excited to see how Theia can contribute to both academic research and practical applications in robotics,” it said. Visit the AI Institute’s project page and demo page to learn more about Theia.





GIPHY App Key not set. Please check settings